Guidelines¶
Here there is a fast overview of the theory behind the algorithm, the challanges that I have encountered during the implementation and how I faced them. It is not intended to be a sophisticated or even perfectly correct treatment, since the project’s scope was a university exam (Introduction to Bayesian Probability Theory by professor Walter Del Pozzo, University of Pisa) and the problem at hand is very difficult. It was not required to obtain exact results. If I will help someone to get an idea of how to handle the problem, I will be happy. Other information can be found in the slides updated into the repository.
Brief Introduction¶
Nested Sampling is an algorithm aimed to evaluate the evidence in the Bayes’ Theorem
where \(H\) is the hypothesis that explain some phenomenon, \(D\) are the data registered and \(I\) is the background information. Keep in mind that usually we can not compute directly the sum over all the possibile hypothesis that explain our phenomenon because they aren’t mutually exclusive (and we don’t have the power to enumerate all of them!). Using the usual names that can be found in the literature
Evidence is one of the most important quantites of the Bayes Probability Theory since it enters in the computation of the so-called Odds Ratio between two competing hypothesis \(H_1\) and \(H_2\).
Odds Ratio reduces to the Bayes Factor when we do not have any prior information that can favor one hypothesis over the other (we have to be fair). Then, writing the Bayes Theorem for the set of parameters on which \(H_1\) and \(H_2\) depend, Bayes Factor becames the ratio between the evidences of the two set of parameters (note that the integrals are actually the ratio of the likelihoods by marginalization)
General Idea¶
We end up with the problem of computing a multidimensional integral of this form
The main idea to image to change variables in such a way that
where \(\xi\) is called the prior mass and it represents the cumulative prior over a specific level of the likelihood. It is defined by
It is clear the meaning of the prior mass looking at the following one dimension uniform prior and gaussian likelihood
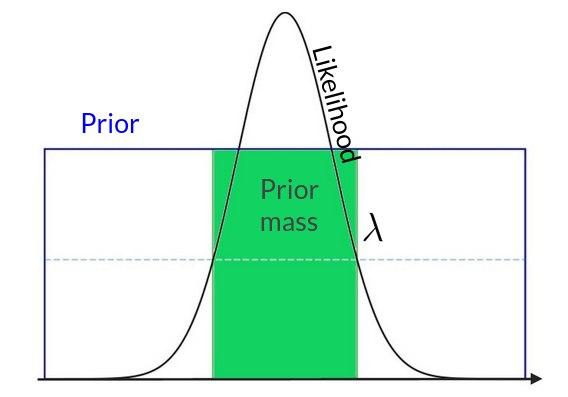
If we were able to find the transformation that maps the prior into the prior mass we would end up with a 1-dim integral over the interval [0,1] insted of an N-dim integral over the entire parameter space. The problem is hugely reduced in terms of computational complexity
The problem is that we do not know this transformation, but Nested Sampling finds it in a statistical way, reasoning on just the fact that the likelihood is a decreasing function of the prior mass. For more details, check the original paper by Skilling (the one published in 2004 or the other in 2006. The book of Sivia and Skilling, Data Analysis, has a great treatement of the subject, too), but to get a general idea of what you have to do, consider the following image that describes in a schematic way the major steps of the algorithm

Termination condition¶
What is this termination condition? Well, we can define it by looking at the typical behaviour of the value of the area element \(L^* \Delta \xi\)
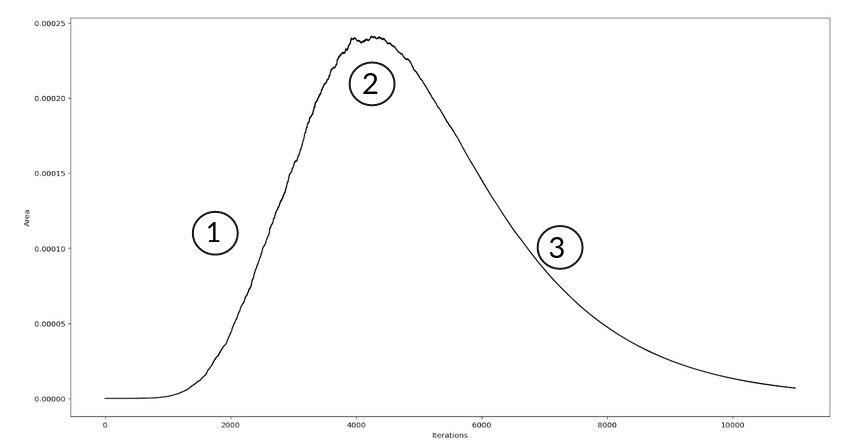
The increase of the likelihood overcomes the decrease of the \(\Delta \xi\) \
Balance
The decrease of the widths \(\Delta \xi\) is dominant over the increase of the likelihood
What we would like to do is to stop the algorithm in the final part of the region 3, where the contribution of the area element to the evidence \(Z\) is negligible compared to the already accumulated \(Z\). Ok, but when do this happen? Well, we have to consider one thing: the major contribution to the evidence is made by that area of the prior mass where the bulk of the posterior mass is present. This fraction usually is to be found in the region of \(\xi \approx e^{-H}\) where \(H\) is the information
that represents in logarithmic form the prior-to-posterior shrinkage (\(\frac{Prior}{Posterior} = e^H \implies Posterior = e^{-H}Prior)\). If each \(\xi_k=e^{-k/n}\), to pass through the bulk of the posterior (and so to reach the region 3) we need to exceed significantly \(nH\) iterations. Of course, this is the theory. In practice we do not have the value of information a priori (indeed we accumulate it through iterations!), so what we can do in order to be sure that we have reached the region 3 is to stop the algorithm when
that corresponds to say that we terminate the algorithm when even the maximum value of our current likelihood values times the total width of the current prior mass domain does not contribute to the evidence by a quantity that is greater than a fraction \(f\) of the current evidence value. \ We can do better substituting the maximum of the likelihood values by the analytical maximum of the likelihood, when we can compute it (for example, in the case of a N-dim gaussian this maximum is \((\frac{1}{\sqrt{2 \pi}})^N\))
Problems I encountered¶
I wanted to compute the following integral
with mean zero and covariance matrix set to identity.
The main problems I encountered were of two forms (as usual!): technical problems and conceptual problems. The formers are related to my python experience in programming that is still pretty low, the latters are due to the tricky part of the algorithm: the replacing of the worst object with a new one satisfying the constraint on the likelihood. I had to find a way to tune the average jump of the walker in the Markov Chain (started from the worst object) in such a way to have a value that was neither too big nor too small. Infact, if it was too big, the constraint on the likelihood would stop the majority of the jumps, slowing down the algorithm too much. On the other hand, if it was too small, the walker would not be able to reach the bulk of the posterior mass in the domain of the prior mass (note that this fraction of the prior mass is the one which has the biggest contribute to the evidence) and you would end up with a sub-estimate of \(Z\). To solve this problem I adopted three ways: at first, I set the average jump (the one called std in the code that you can find in nested_sampling function and proposal function) as the mean of the standard deviations over the axis of the parameter space. In this way I grab the average distances between points. Instead, for the normal proposal distribution case, I tuned a proportionality constant to this std in such a way that with the rising of the dimension it becames smaller and smaller. To be clear, what I did is to set the standard deviation of the normal distribution centered in the worst object as
Instead, for the uniform proposal distribution, I tried to keep the acceptance ratio (accepted points/rejected points) to 50%, multipling of dividing std by
Of course these are not the best or unique ways to handle the problem of tuning the parameters of the proposal distribution, but it is what I have done.
Warning
We know the theoretical result of the integral: it is minus the logarithm of the volume of the hypercube on which we are integrating
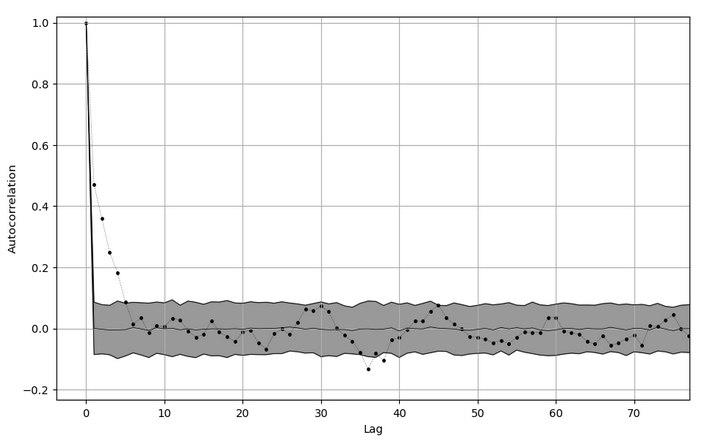
Another aspect with which I had to deal is the autocorrelation between points during the Markov chain procedure in the replacing of the worst object (the one with the smallest likelihood) with a new one sampled from the (uniform) prior. We want a new indipendet object, but obviously we need to start somewhere. I chose to start directly from the parameters corresponding to the worst object and, every time a new point statisfies the constraint on the likelihood, the center of the proposal distribution is shifted into this new accepted point. The question is: how much steps do I have to perform until memory about the starting point is lost? To answer this we can compute the autocorrelation function between, say, 200 accepted point and check when it becames sufficiently small. To quantify this “sufficiently small” I performed a bootstrap test on the time series of accepted points. The gray area in the image below represents the \(\mu \pm 2\sigma\) of the ensamble of 200 autocorrelation vectors obtained by shuffling 200 times the time series of accepted points (so: shuffle -> compute autocorrelation -> append this vector to a list -> repeat 200 times). The shuffling ensures all the temporal relations to be lost, so what remains is an artifact. I assumed that this behaviour of the autocorrelation is the same at every iteration, so every time a new object is required.
Warning
I figured out I made a mistake in the computation of autocorrelation. You have to consider ALL the points (both rejected and accepted ones) in order to evaluate the autocorrelation lenght!